Last week, at my local PASS chapter (Rochester), I gave a presentation titled “Magical Query Tuning.” In the presentation, I described a query-tuning technique that can be used when you think you’re out of options. I first learned of this method from Kendra Little at LittleKendra.com and I think it’s an incredibly interesting and not widely-known method, which is why I chose to share it with everyone.
For the demo, I used the AdventureWorks sample database from Microsoft.
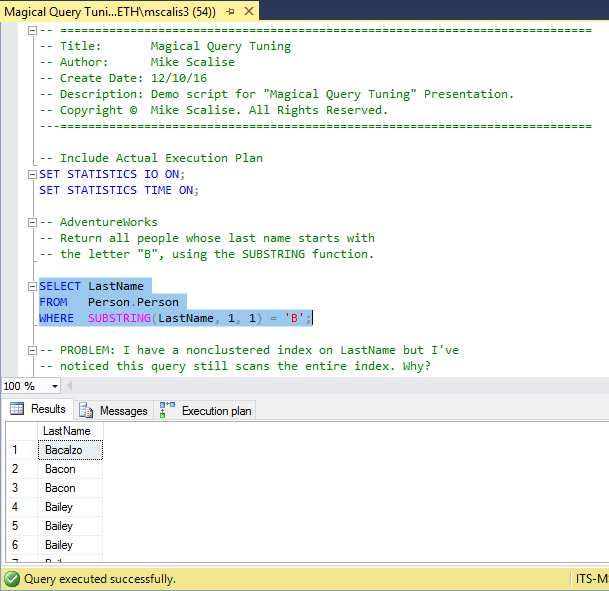
I started with this query. It simply searches the Person table for all people whose last name begins with the letter “B” and displays the last name. “LastName” is the only field used in the query and there is already a non-clustered index on the column. I’ve included the actual execution plan (Ctrl + M) and set TIME and IO statistics on so that we can see all of the details.
(1205 row(s) affected)
Table ‘Person’. Scan count 1, logical reads 106, physical reads 0, read-ahead reads 104, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 15 ms, elapsed time = 92 ms.
We can see that there are 1205 people whose last name starts with the letter “B”. The query took about 92 ms to complete and required 106 logical and 104 read-ahead reads.
Here’s the actual execution plan:
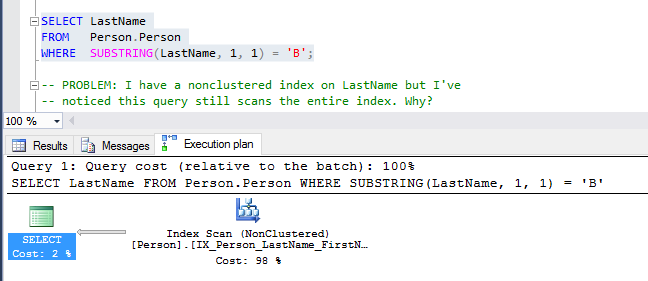
According to the actual execution plan, the query optimizer used the non-clustered index “IX_Person_LastName_FirstName_MiddleName”, which is good, but notice how it had to scan the entire index rather than seek to find the last names we’re looking for. Why? What prevented the seek?
Answer: The SUBSTRING function in the WHERE clause. It doesn’t matter that there’s an index on the “LastName” column. Once a function is applied to that column, the possibility of an index seek gets thrown out the window. This means that the predicate, which was once SARGable (Search ARGument-able), is now non-SARGable. So how can we get it back to being SARGable so that SQL Server can seek on the index?
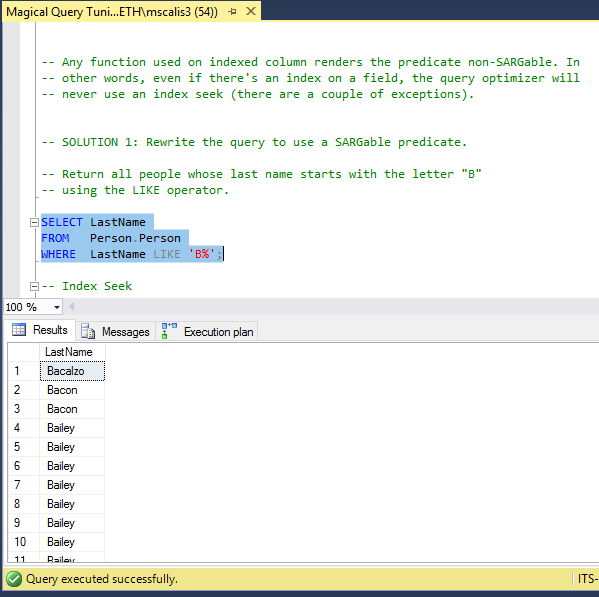
One option is to rewrite the query so that it returns the same results without using a function in the predicate and instead uses a SARGable operator (i.e., the LIKE operator):
(1205 row(s) affected)
Table ‘Person’. Scan count 1, logical reads 10, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 82 ms.
Notice how this version of the query took 82 ms to complete and required only 10 logical reads and 0 read-ahead reads. Getting better!
Here’s the actual execution plan:
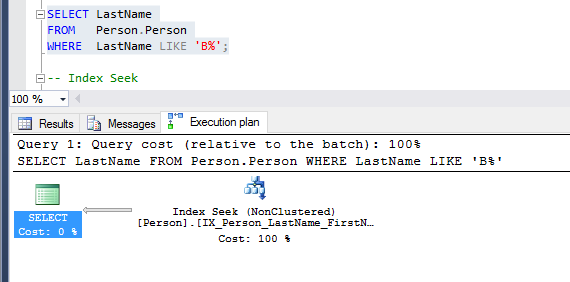
According to the plan, the same non-clustered index was used and an index seek was achieved!
These are all great improvements–a faster query that requires fewer reads, and performs a seek operation by leveraging an index on the field.
HOWEVER, what if we don’t have any control over the query and therefore can’t re-write it? Maybe the inefficient query is built and issued by an application and we’re stuck with a function in the WHERE clause. What options do we have now? We could beg the vendor to issue a patch, I suppose. But then we’re at the mercy of the vendor. If the query performance issue needs to be addressed immediately, there’s an interim solution you can try.
In our scenario, I’m going to start by creating a computed column in the Person table. The formula for the computed column will exactly match the one in the where clause of our inefficient query — “SUBSTRING(LastName, 1, 1)”. Then, I’m going to create a non-clustered index on that newly-created computed column and call it “IX_LastNameInitial”.
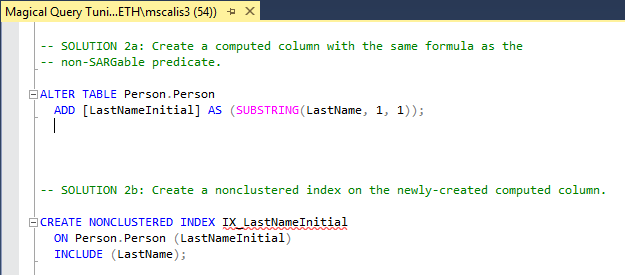
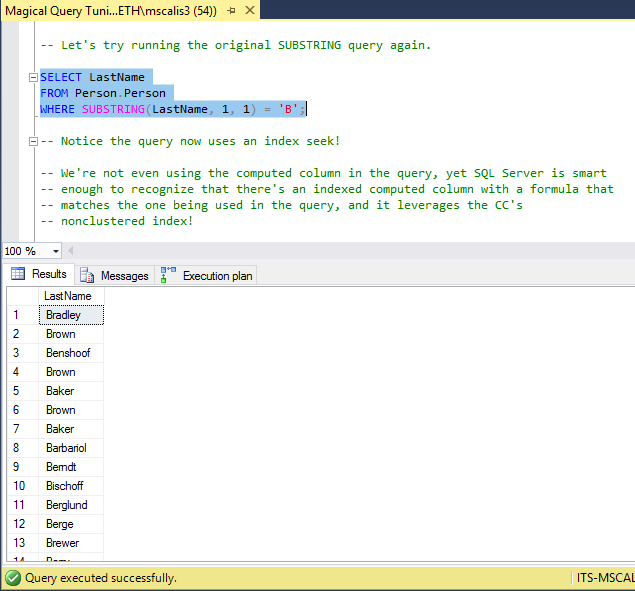
Let’s run the original, inefficient query again.
(1205 row(s) affected)
Table ‘Person’. Scan count 1, logical reads 7, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 79 ms.
This time the query took only 79 ms, and required only 7 logical and 0 read-ahead reads!
Here’s the actual execution plan:
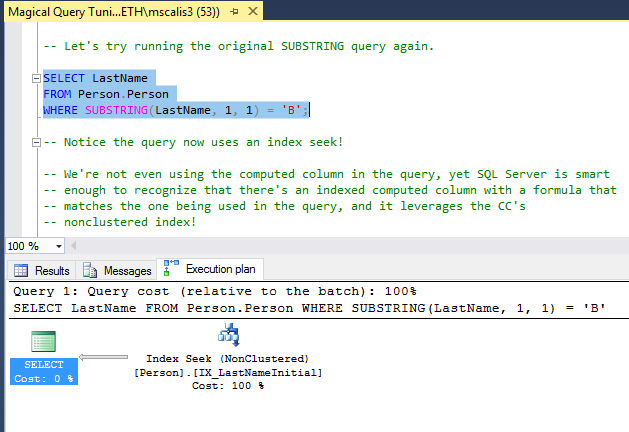
This time we get an index seek! SQL Server is smart enough to match the formula in the WHERE clause with one contained within the computed column we created and leverage its non-clustered index (“IX_LastNameInitial”), despite not using the computed column in the query!
Now we have our fastest performing query (unchanged), using an index seek and with the fewest logical and read-ahead reads. The best of all worlds, given our situation.
Let’s clean up:
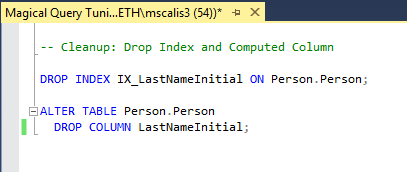
In summary, if you find yourself in a situation where you can’t re-write a poorly-performing query issued by an application, beg the vendor to issue an update, throw more memory or CPU at the problem, etc. Use this technique when you’ve exhausted those options first. This option requires a structural change to one or many tables and the creation of indexes, which may void a warranty or, at the very least, add some maintenance to existing maintenance plans…but that may be acceptable in your specific situation.
You can download the PowerPoint presentation and SQL script here.
Mike